
こんにちは、香田です。
今回はCloud Workflowsを使用してBigQuery 日付別テーブルのデータを分割テーブルへ移行する方法について紹介していきます。
利用する日付別テーブルとしては、Google アナリティクス 4で提供されているBigQuery Exportで生成されたテーブルを利用していきます。
Google アナリティクス 4のBigQuery Exportについては、以前下記の記事に記載してますのでよかったら参考にしてみてください。
BigQuery 分割テーブルのスキーマ作成
はじめにデータ移行元となるGoogle アナリティクス 4のBigQuery Exportで生成されたテーブルよりスキーマ定義を取得します。
BigQuery Exportでは下記のような日付別テーブルが作成されているはずです。
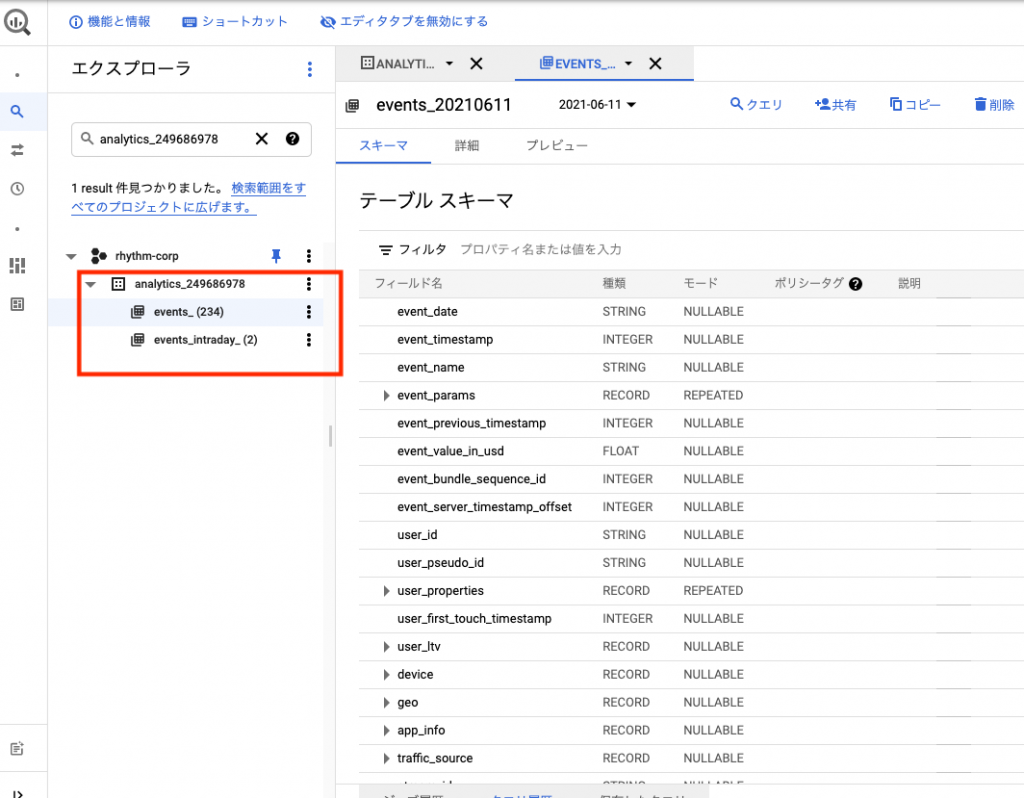
下記のようにbqコマンドにて、日付別テーブルのスキーマ定義をJSON形式で取得します。
bq show --schema --format=prettyjson \
analytics_<property_id>.events_<yyyymmdd> > events_schema.json別途、分割テーブルのパーティショニング列として追加する列のJSONファイルをpartitioned_date.jsonという名前で作成します。
[
{
"mode": "NULLABLE",
"name": "partitioned_date",
"type": "DATE"
}
]jqコマンドを利用し日付別テーブルのスキーマが定義されたJSONファイルへパーティショニング列を末尾に追加します。
jq -s add events_schema.json partitioned_date.json > schema.jsonBigQuery 分割テーブルの作成
次に分割テーブルを作成していきます。
データセットとしてsample_datasetを作成します。
bq mk --dataset sample_dataset作成したスキーマ定義を利用し分割テーブルを作成します。
bq mk --table \
--schema ./schema.json \
--time_partitioning_field partitioned_date \
--require_partition_filter \
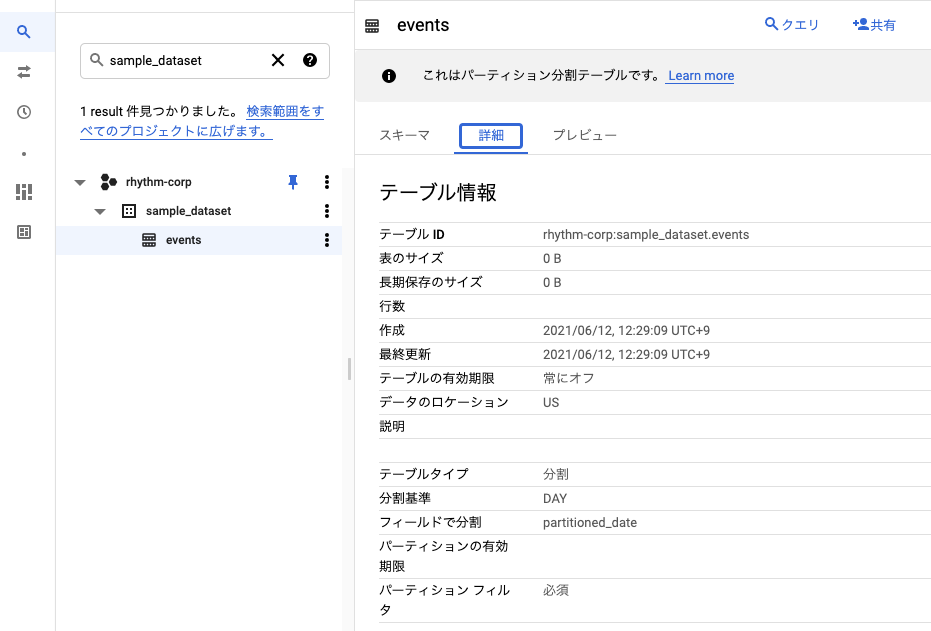
sample_dataset.events下記のような分割テーブルが作成されていれば成功です。
ワークフローの作成
次にCloud Workflowsでワークフローを作成していきます。
ワークフローの内容は、前日分の日付別テーブルのデータを作成した分割テーブルへINSERTする内容となります。
下記の内容を元にworkflow.yamlという名前でファイルを作成します。
変数設定の箇所で指定しているsrcDatasetIdは、BigQuery Exportで生成された日付別テーブルのデータセットIDを指定してください。
main:
steps:
# 変数設定
- initialize:
assign:
- projectId: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- srcDatasetId: analytics_<property_id>
- destDatasetId: sample_dataset
- destTableId: events
# 日付情報をBigQueryより取得する
- runSelectQuery:
call: http.post
args:
url: ${"https://bigquery.googleapis.com/bigquery/v2/projects/"+projectId+"/queries"}
auth:
type: OAuth2
body:
useLegacySql: false
query: SELECT DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY) AS part_date,
FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) AS f_part_date
result: queryResults
next: parseResults
# 取得した日付を変数へセットする
- parseResults:
assign:
- partitionedDate: ${queryResults.body.rows[0].f[0].v} # yyyy-mm-dd がセットされる
- srcTableId: ${"events_"+queryResults.body.rows[0].f[1].v} # events_yyyymmdd がセットされる
next: getTable
# Table 存在確認
- getTable:
try:
call: http.get
args:
url: ${"https://bigquery.googleapis.com/bigquery/v2/projects/"+projectId+"/datasets/"+srcDatasetId+"/tables/"+srcTableId}
auth:
type: OAuth2
result: tableResult
except:
as: e
steps:
- is_the_key_found:
switch:
- condition: ${e.code == 404}
next: tableNotFound
next: runDeleteQuery
# テーブルが存在しない場合は終了
- tableNotFound:
return: "Table not found."
# データ削除
- runDeleteQuery:
call: http.post
args:
url: ${"https://bigquery.googleapis.com/bigquery/v2/projects/"+projectId+"/queries"}
auth:
type: OAuth2
body:
useLegacySql: false
query: ${"DELETE FROM "+destDatasetId+"."+destTableId+"
WHERE partitioned_date = '"+partitionedDate+"'"}
next: runInsertSelectQuery
# データ挿入
- runInsertSelectQuery:
call: http.post
args:
url: ${"https://bigquery.googleapis.com/bigquery/v2/projects/"+projectId+"/queries"}
auth:
type: OAuth2
body:
useLegacySql: false
query: ${"INSERT INTO "+destDatasetId+"."+destTableId+"
SELECT *, PARSE_DATE('%Y%m%d', event_date) AS partitioned_date
FROM "+srcDatasetId+"."+srcTableId}
result: queryResults
next: queryCompleted
- queryCompleted:
return: ${queryResults}ワークフローをデプロイ
作成したYAMLファイルを指定し、ワークフローをデプロイします。
gcloud beta workflows deploy migrate-to-partitioned-table \
--source=workflow.yaml \
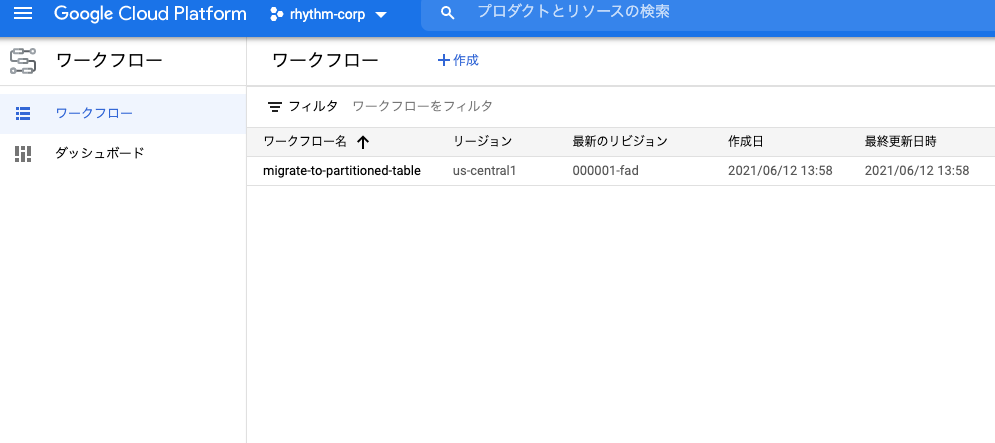
--location=us-central1デプロイすると下記のようにワークフローが確認できるはずです。
ワークフローの実行
デプロイしたワークフローを実行していきます。
gcloud beta workflows run migrate-to-partitioned-table \
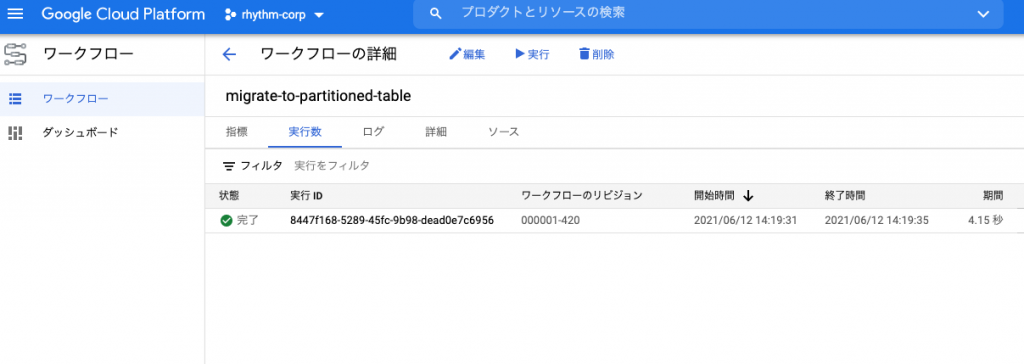
--location=us-central1実行に問題なければ下記のように完了と表示されているはずです。
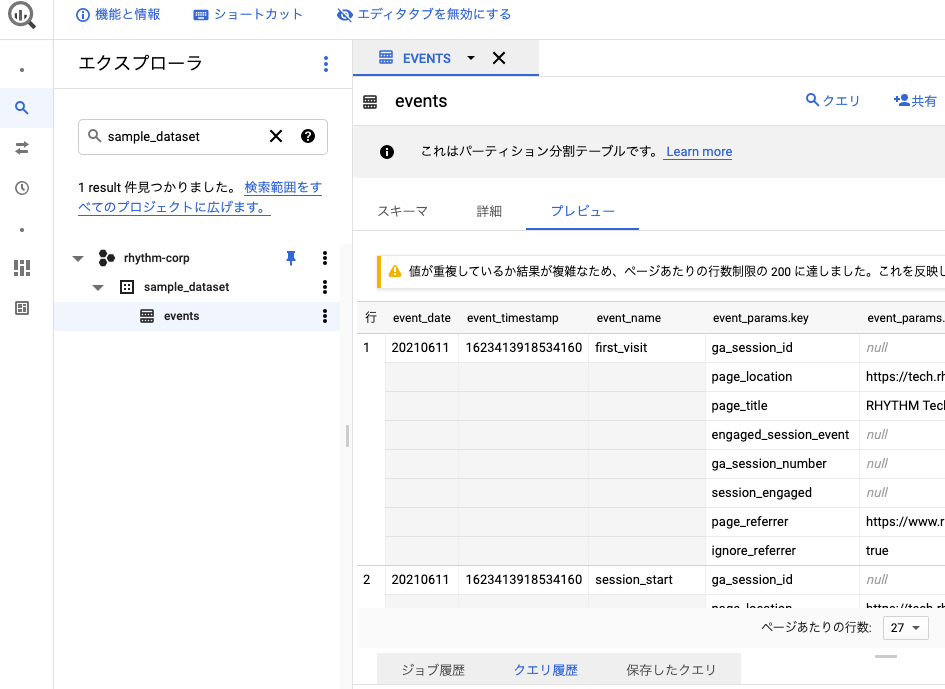
最終的に作成した分割テーブルへ前日の日付別テーブルのデータが確認できれば成功です。
さいごに
Cloud Workflowsを使用してBigQuery 日付別テーブルのデータを分割テーブルへ移行する方法いかがでしたでしょうか。
作成したワークフローをスケジュール実行したい場合は、Cloud Schedulerを利用すれば可能となります。
スケジュール実行については以前下記の記事に記載してますので、よかったら参考にしてみてください。
最後までご覧いただきありがとうございます。