
こんにちは、香田です。
今回はCloud Workflowsを使用してGCSのデータをBigQueryへロードする方法について紹介していきます。
Cloud Workflowsの概要についてはこちらを参考にしてみてください。
GCSに保存されているデータの構成
はじめにBigQueryへロードするGCSのデータについて説明しておきます。
利用するGCSのデータですが、下記のように日付ごとのフォルダにデータが保存される構成を想定しています。
gs://sample-workflows
├─ 2020-06-05
│ └── data.csv
├─ 2020-06-06
│ └── data.csv
└─ 2020-06-07
└── data.csvデータの中身は下記のような内容です。
customer_id,first_name,last_name,email,create_date
80,Marilyn,Ross,marilyn.ross@example.com,2020-06-05
30,Melissa,King,melissa.king@example.com,2020-06-05
60,Mildred,Bailey,mildred.bailey@example.com,2020-06-05BigQueryのテーブル構成
次にデータがロードされるBigQueryのテーブルを事前に作成しておきます。
BigQueryのスキーマは下記のような内容で、分割テーブルとして作成していきます。
- テーブルのスキーマJSONファイル
[
{
"mode": "NULLABLE",
"name": "customer_id",
"type": "INTEGER"
},
{
"mode": "NULLABLE",
"name": "first_name",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "last_name",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "email",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "create_date",
"type": "DATE"
}
]データセット名sampleを作成します。
$ bq mk sample分割テーブルとしてcustomerテーブルを作成します。
$ bq mk --table \
--schema ./schema.json \
--time_partitioning_field create_date \
--require_partition_filter \
sample.customerワークフローの作成
次にCloud Workflowsでワークフローを作成していきます。
2020年12月10日のリリースより、コンソール画面のワークフローの定義で可視化が搭載されたようなので、今回はコンソール画面を利用していきます。
コンソール画面より[ワークフロー]を選択し、[作成]をクリックします。
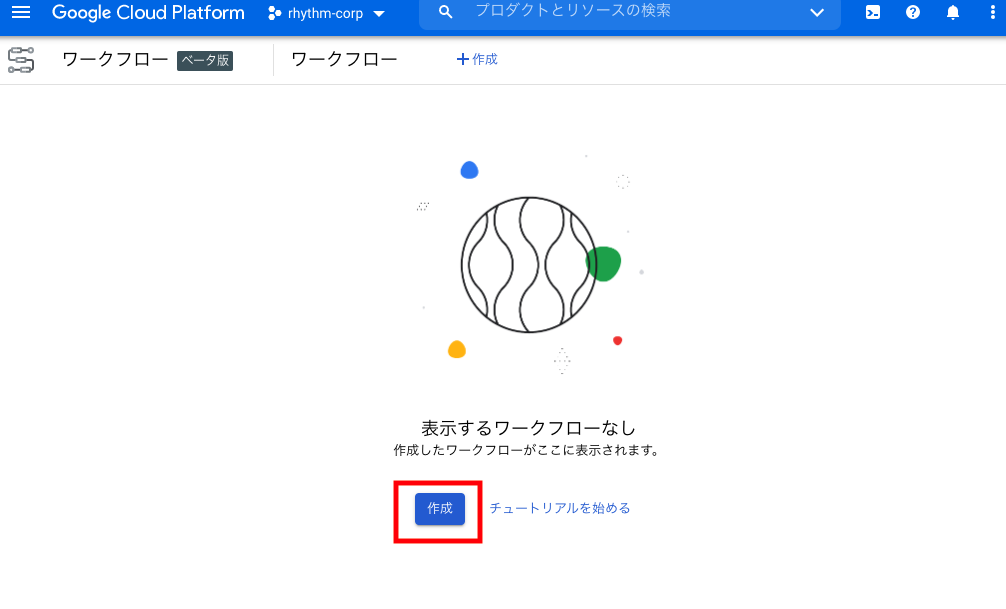
[ワークフロー名]、[リージョン]、[サービスアカウント]を適宜入力し、[次へ]をクリックします。
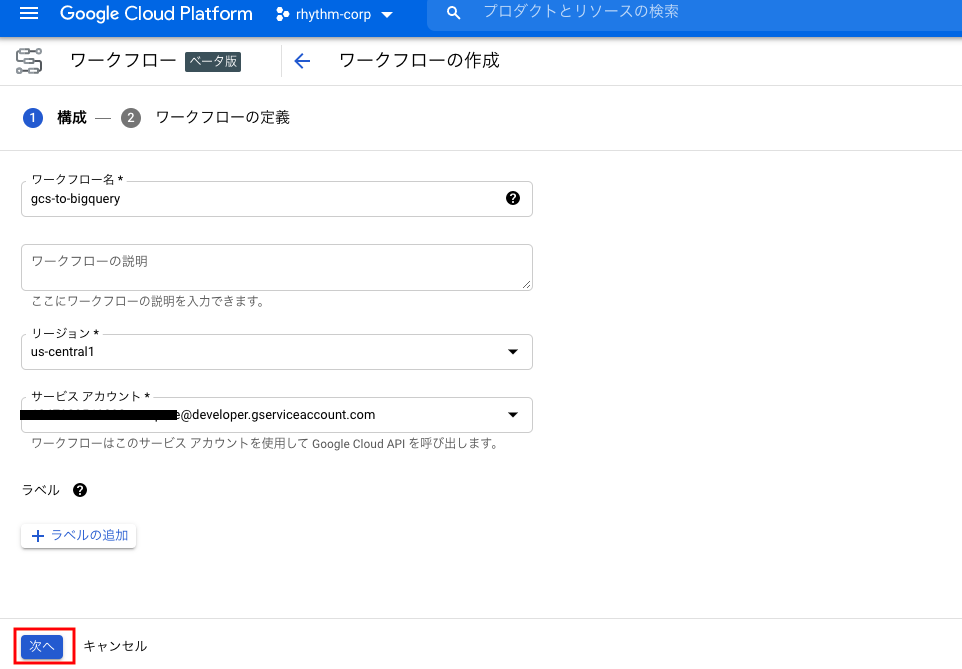
[ワークフローの定義]に下記のyamlをコピーし貼り付けます。
stepsのinitializeにて変数設定しているbucketNameはGCSのバケット名になるので、適宜修正してください。
main:
steps:
# 変数設定
- initialize:
assign:
- projectId: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- bucketName: sample-workflows
- datasetId: sample
- tableId: customer
- schema:
fields:
- name: "customer_id"
type: "INTEGER"
- name: "first_name"
type: "STRING"
- name: "last_name"
type: "STRING"
- name: "email"
type: "STRING"
- name: "create_date"
type: "DATE"
# 現在の日付をBigQueryより取得する
- runSelectQuery:
call: http.post
args:
url: ${"https://bigquery.googleapis.com/bigquery/v2/projects/"+projectId+"/queries"}
auth:
type: OAuth2
body:
useLegacySql: false
query: "SELECT CURRENT_DATE() as the_date"
result: queryResult
next: parseResults
# 取得した日付を変数へセットする
- parseResults:
assign:
- targetDate: ${queryResult.body.rows[0].f[0].v}
next: runDeleteQuery
# 冪等性担保の為、分割基準の列に対して日付指定しデータ削除
- runDeleteQuery:
call: http.post
args:
url: ${"https://bigquery.googleapis.com/bigquery/v2/projects/"+projectId+"/queries"}
auth:
type: OAuth2
body:
useLegacySql: false
query: ${"DELETE FROM "+datasetId+"."+tableId+" WHERE create_date = '"+targetDate+"'"}
next: runLoadJob
# BigQueryへGCSのデータをロードする
- runLoadJob:
call: http.post
args:
url: ${"https://bigquery.googleapis.com/bigquery/v2/projects/"+projectId+"/jobs"}
auth:
type: OAuth2
body:
configuration:
jobType: LOAD
load:
sourceUris: ${"gs://"+bucketName+"/"+targetDate+"/*.csv"}
skipLeadingRows: 1
schema: ${schema}
destinationTable:
projectId: ${projectId}
datasetId: ${datasetId}
tableId: ${tableId}
result: jobResult
next: jobResults
- jobResults:
return: ${jobResult.body}下記のようにワークフローが可視化されることが確認できます。問題なければ[デプロイ]をクリックします。
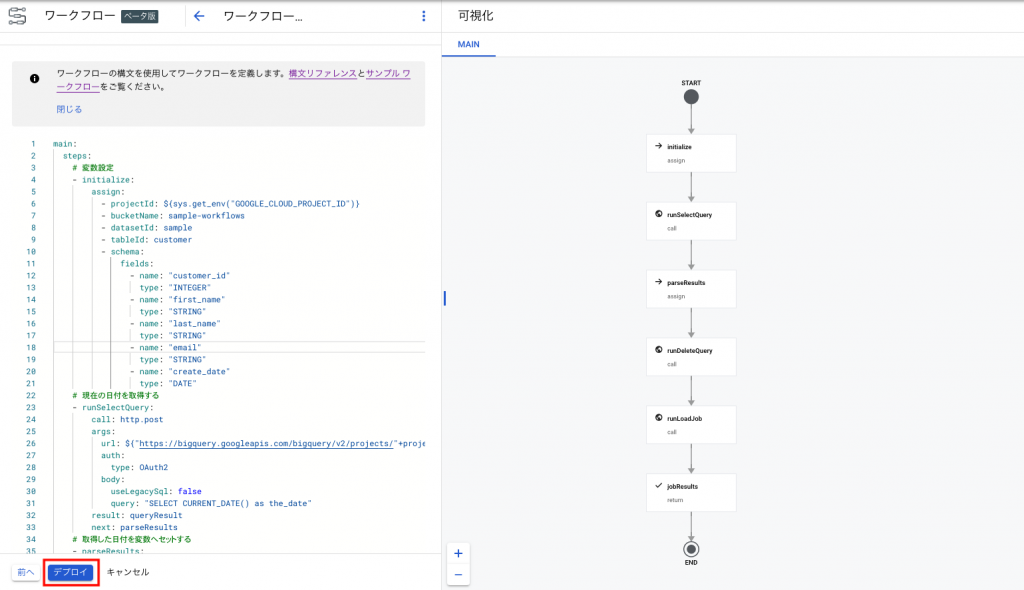
[ワークフローの詳細]より[実行]をクリックします。しばらくすると下記のように実行後の状態が表示されます。
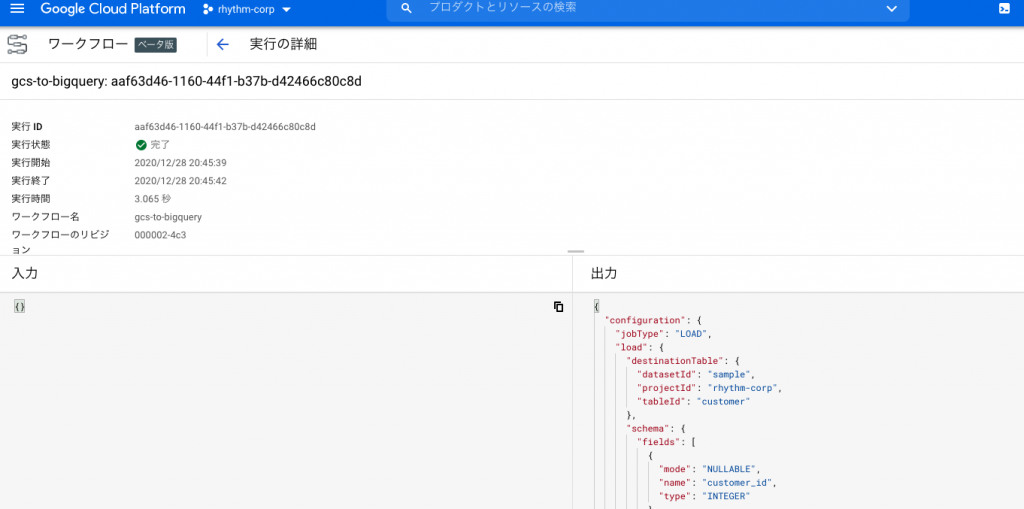
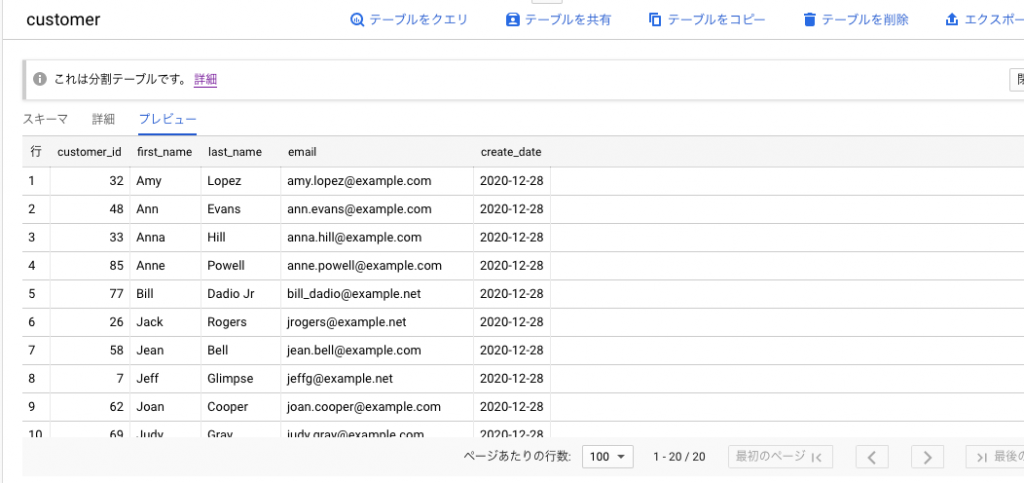
実行結果として、下記のようにBigQueryのテーブルへロードされていれば成功です。
さいごに
Cloud Workflowsを使用してGCSのデータをBigQueryへロードする方法いかがでしたでしょうか。
サーバーレスにGCSのデータをBigQueryへロードしたい場合、一つの選択肢として有効ではないでしょうか。
ワークフローのスケジュール実行については、以前記載致しましたのでよかったら参考にしてみてください。
Cloud Workflowsを使用してワークフローをスケジュール実行する
最後までご覧いただきありがとうございます。